Tính toán chính xác dòng chảy trên sông là nền tảng trong việc quản lý tài nguyên nước hiệu quả và giảm thiểu rủi ro lũ lụt. Ở những khu vực có lượng mưa biến động lớn hoặc những nơi thường xảy ra hiện tượng thời tiết khắc nghiệt, như lũ lụt hoặc hạn hán, việc hiểu và dự báo lưu lượng nước rất quan trọng để quản lý những rủi ro này. Tuy nhiên, việc đạt được dự đoán dòng chảy chính xác là một thách thức do sự tương tác phức tạp và động lực học giữa lượng mưa, địa hình, thảm phủ thực vật, đặc điểm loại đất và các yếu tố cụ thể khác của từng khu vực. Các mô hình thủy văn truyền thống, như MIKE-NAM - mô phỏng các quá trình vật lý của dòng chảy từ mưa, hoặc mô hình dựa trên dữ liệu như học máy, học sâu, mang lại nhưng lợi thế khác nhau trong việc mô phỏng mưa - dòng chảy. Mô hình mô phỏng mưa - dòng chảy đã có một lịch sử lâu dài trong khoa học thủy văn. Những nghiên cứu đầu tiên để dự đoán lưu lượng từ các trận mưa bằng cách sử dụng các phương pháp hồi quy đã có từ 170 năm trước. Kể từ đó, các khái niệm mô hình hóa đã được phát triển không ngừng bằng cách dần dần kết hợp các khái niệm dựa theo các công thức mô hình (toán học).
Chúng bao gồm việc giải quyết sự biến đổi không gian của các quá trình, điều kiện biên và tính chất vật lý của lưu vực. Tuy nhiên, sự phát triển theo hướng kết hợp, dựa trên công thức vật lý và không gian của các quá trình thủy văn ở quy mô lưu vực thường phải đánh đổi bằng chi phí tính toán cao và yêu cầu rất lớn đối với dữ liệu đầu vào. Gần đây, một cách tiếp cận khác là sử dụng các thuật toán học máy (machine learning) và học sâu (deep learning). Đối với các vấn đề thủy văn, chuỗi số liệu đầu vào là quá trình liên tục theo thời gian, kiến trúc mạng tiên tiến nhất hiện nay LSTM được ứng dụng cho các kết quả rất hứa hẹn. LSTM đã được ứng dụng rộng rãi và thành công trong dự báo thủy văn ở nhiều nơi trên thế giới, nhưng ở Việt Nam vẫn còn hạn chế.
Cả hai cách tiếp cận MIKE NAM và LSTM đều có những ưu điểm và nhược điểm riêng biệt trong tính toán mưa - dòng chảy. MIKE NAM mô phỏng các quá trình vật lý của lưu vực, phù hợp để thể hiện tương tác giữa lượng mưa - lưu lượng dựa trên các nguyên tắc cân bằng nước. Điểm mạnh nằm ở khả năng kết hợp các đặc điểm lưu vực và các thông số vật lý, giúp tăng cường khả năng diễn giải. Tuy nhiên, MIKE NAM yêu cầu lượng dữ liệu đầu vào lớn và có thể gặp khó khăn trong việc nắm bắt các tính chất phi tuyến tính và tương tác phức tạp trong các sự kiện cực đoan. Ngược lại, LSTM, một mô hình học máy, lại xuất sắc trong việc học các mô hình phức tạp và các mối quan hệ phi tuyến tính trực tiếp từ dữ liệu mà không cần các thông số vật lý rõ ràng. Điều này giúp linh hoạt và có khả năng nắm bắt các sắc thái trong diễn biến mưa - dòng chảy, đặc biệt là trong các trận lũ lớn. Tuy nhiên, LSTM phụ thuộc rất nhiều vào các tập dữ liệu lớn, chất lượng cao và thiếu khả năng diễn giải tính chất vật lý của các mô hình, khiến nó trở thành một phương pháp tiếp cận "hộp đen" hơn. Ngoài ra, các mô hình LSTM có thể dễ bị quá khớp (overfitting) nếu không được đào tạo đúng cách và có thể gặp khó khăn khi ngoại suy vượt ra ngoài phạm vi dữ liệu được sử dụng trong quá trình huấn luyện.
Do vậy các nhà khoa học của Phòng Thí nghiệm trọng điểm quốc gia về động lực học sông biển thuộc Viện Khoa học Thủy lợi Việt Nam gồm: Hoàng Đức Vinh, Lê Văn Nghị, Nguyễn Ngọc Nam và Ngô Quang Hồng Sơn đã thử nghiệm tính toán dòng chảy trên sông Hiếu, tại Trạm thủy văn Nghĩa Khánh với hai cách tiếp cận gồm mô hình dựa trên công thức vật lý truyền thống - MIKE NAM và mô hình học sâu, dựa vào dữ liệu LSTM. Các dữ liệu đầu vào bao gồm chuỗi mưa, bốc hơi, lưu lượng ngày từ năm 1975 đến năm 2020. Trong mô hình LSTM, các nhà khoa học đã thử nghiệm điều kiện đầu vào gồm: mưa, bốc hơi - đặt tên là LSTM-X; mưa, bốc hơi, lưu lượng tại Quỳ Châu - đặt tên là LSTM-Q. Từ đó so sánh hiệu suất của các mô hình, nhằm xác định mô hình nào cung cấp các dự đoán đáng tin cậy hơn trong các điều kiện thủy văn khác nhau, góp phần đưa ra quyết định sáng suốt hơn trong quản lý tài nguyên nước và giảm nhẹ thiên tai.
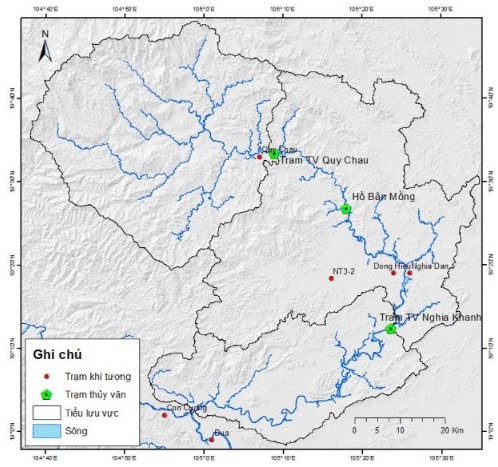
Lưu vực sông Hiếu và vị trí các trạm khí tượng, thủy văn thực hiện nghiên cứu.
Kết quả nghiên cứu của các nhà khoa học cho thấy, cả 3 mô hình thử nghiệm đều có thể dự đoán tốt đối với xu thế mùa lũ, mùa kiệt của toàn bộ chuỗi thời gian. Tuy nhiên, có thể thấy rằng, đối với những con lũ lớn (ví dụ năm 1988, 2007 và 2017), đỉnh lũ vượt quá 3500 m3/s, thì các mô hình đều dự đoán lưu lượng thấp hơn. Điều này được giải thích là do các trận lũ lớn vốn xảy ra không thường xuyên, đặc biệt là các trận lũ cực đoan trên 4000 m3/s, chỉ xảy ra 4 lần trong chuỗi 46 năm, nên số lượng không đủ để mô hình học một cách tốt nhất. Số lượng đỉnh lũ lớn ít trong tập dữ liệu làm cho mô hình gặp khó khăn trong việc khái quát hóa các sự kiện này, dẫn đến sai số dự đoán cao.
Khi so sánh ba mô hình, LSTM-Q luôn chứng minh hiệu suất vượt trội trên cả tập dữ liệu đào tạo và kiểm định. Đối với toàn bộ tập dữ liệu, LSTM-Q đạt hiệu quả Nash cao nhất (0,90 cho đào tạo và 0,80 cho kiểm định), kèm theo RMSE thấp nhất (69,67 trong đào tạo và 99,01 trong thử nghiệm) và MAE (24,13 trong đào tạo và 29,30 trong thử nghiệm). Điều này cho thấy sự phù hợp tốt hơn và lỗi thấp hơn cả LSTM-X và MIKE NAM. Mặt khác, MIKE NAM, mặc dù cho thấy các giá trị Nash cạnh tranh cho toàn bộ dữ liệu (0,80 trong hiệu chỉnh và 0,78 trong kiểm định), nhưng lại có giá trị RMSE và MAE cao hơn đáng kể, đặc biệt là trong mùa lũ, khi ghi nhận RMSE và MAE cao nhất trong tất cả các mô hình.
Khi phân tích hiệu suất theo mùa, LSTM-Q một lần nữa vượt trội hơn trong cả mùa lũ và mùa khô. Nó đạt được các giá trị Nash cao hơn trong cả mùa lũ (0,89 trong quá trình huấn luyện, 0,77 trong quá trình kiểm định) và mùa khô (0,86 trong quá trình huấn luyện, 0,76 trong quá trình kiểm định) so với MIKE NAM và LSTM-X. Các giá trị RMSE và MAE của LSTM-Q trong mùa khô đặc biệt thấp cho thấy khả năng dự đoán tốt hơn trong các giai đoạn mùa khô, điều này có thể cho thấy độ nhạy tốt hơn với các điều kiện dòng chảy thấp. Ngược lại, LSTM-X cho thấy hiệu suất đào tạo tương đối mạnh, đặc biệt là trong mùa lũ (Nash là 0,85), nhưng lại giảm đáng kể hiệu suất trong quá trình kiểm định, đặc biệt là trong mùa lũ khi RMSE tăng lên 186,44, cao hơn cả MIKE NAM và LSTM-Q. Nhìn chung, LSTM-Q cung cấp khả năng dự đoán cân bằng và mạnh mẽ hơn trong mọi điều kiện.
Đối với giai đoạn huấn luyện, lưu lượng đỉnh trung bình thực đo là 2221,69 m3/s và trong số các mô hình, LSTM-Q dự đoán giá trị gần nhất là 2072,36 m3/s, với sai số nhỏ nhất là 318,11 m3/s. LSTM-X theo sau với dự đoán là 1945,24 m3/s và sai số là 362,06 m3/s, trong khi MIKE NAM với dự đoán trung bình là 1769,52 m3/s và sai số lớn hơn đáng kể là 544,41 m3/s. Điều này nhấn mạnh rằng, LSTM-Q là mô hình chính xác nhất trong việc ước tính đỉnh lũ trong giai đoạn huấn luyện.
Trong giai đoạn kiểm định, đỉnh lũ trung bình thực đo là 2302,20 m3/s. LSTM-Q một lần nữa tạo ra kết quả chính xác nhất, với mức trung bình dự đoán là 2338,70 m3/s và sai số là 520,47 m3/s, gần giống với dữ liệu quan sát được. MIKE NAM đánh giá thấp đỉnh lũ trung bình (1767,01 m3/s) nhưng vẫn hoạt động tốt hơn LSTM-X, dự đoán là 2019,22 m3/s. LSTM-X có sai số cao nhất là 730,99 m3/s cho thấy gặp nhiều khó khăn hơn trong giai đoạn kiểm định. Nhìn chung, LSTM-Q luôn vượt trội hơn các mô hình khác, cho thấy độ tin cậy tốt hơn trong việc dự đoán đỉnh lũ hằng năm.
Những kết quả trên cho thấy, việc sử dụng thêm lưu lượng tại Quỳ Châu làm đầu vào cho mô hình LSTM có ý nghĩa rất tích cực trong việc tăng cường khả năng dự đoán chính xác lưu lượng tại Nghĩa Khánh. Điều này được giải thích là do khi kết hợp dữ liệu Q thượng nguồn, LSTM có thể cải thiện khả năng hiểu biết về động lực của lưu vực bằng cách nắm bắt các mối phụ thuộc về không gian và thời gian giữa các trạm thủy văn với nhau. Lưu lượng tại Quỳ Châu cũng tăng cường khả năng dự đoán chính xác cách nước lan truyền qua hệ thống của mô hình, đặc biệt là trong các trận lũ lớn. Do đó, LSTM-Q vượt trội trong việc ước tính cả điều kiện dòng chảy bình thường và đỉnh lũ hơn hẳn MIKE-NAM và LSTM-X trong tất cả các số liệu chính.
Công Thường