Trong 25 năm đầu thế kỷ XXI, khoa học thế giới đã chứng kiến những đột phá mang tính bước ngoặt như: vắc-xin mRNA, kỹ thuật chỉnh sửa gen dựa trên CRISPR, phát hiện hạt Higgs và đo được sóng hấp dẫn lần đầu tiên. Tuy nhiên, không một nghiên cứu nào trong số này góp mặt trong danh sách các bài báo khoa học được trích dẫn nhiều nhất kể từ năm 2000.
Đây là một trong những phát hiện từ phân tích của nhóm phóng viên Nature, nhằm xác định 25 bài báo khoa học có số lượt trích dẫn cao nhất trong thế kỷ XXI. Các công trình dẫn đầu danh sách không tập trung vào các nghiên cứu gây chấn động, mà chủ yếu xoay quanh các chủ đề như trí tuệ nhân tạo (AI), phương pháp cải thiện chất lượng nghiên cứu và tổng quan hệ thống, thống kê ung thư và phần mềm hỗ trợ nghiên cứu. Duy nhất một nghiên cứu mang tính khám phá - bài báo năm 2004 về thí nghiệm với graphene, từng giúp tác giả giành Giải Nobel Vật lý năm 2010 góp mặt trong top được trích dẫn nhiều nhất.
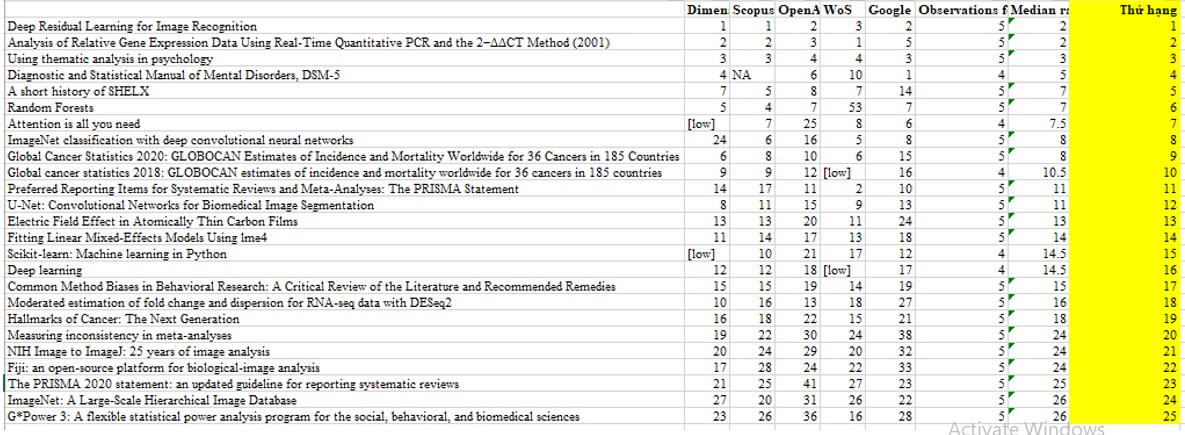
25 công trình được trích dẫn nhiều nhất thế kỷ XXI (nguồn: Nature).
Trích dẫn học thuật là cách để giới khoa học ghi nhận các công trình nghiên cứu trước đó và được xem là thước đo quan trọng về mức độ ảnh hưởng của một nghiên cứu. Tuy nhiên, những bài báo được trích dẫn nhiều nhất thường không phải là những khám phá nổi tiếng nhất. Thay vào đó, chúng thường mô tả phương pháp, lý thuyết hoặc phần mềm - các “công cụ thầm lặng” mà cộng đồng khoa học thường xuyên sử dụng.
Hiện có nhiều cơ sở dữ liệu thống kê trích dẫn học thuật, mỗi nơi lại theo dõi các tập tài liệu và ghi nhận số lượt trích dẫn khác nhau. Trong phân tích của Nature, họ đã lựa chọn 5 cơ sở dữ liệu lớn và xác định thứ hạng trung vị của mỗi bài báo. Các cơ sở dữ liệu này bao phủ hàng chục triệu công trình khoa học được xuất bản kể từ đầu thế kỷ XXI.
Bài báo về mạng học sâu ResNet dẫn đầu trích dẫn trong thế kỷ XXI
Theo phương pháp phân tích của Nature, bài báo khoa học được trích dẫn nhiều nhất trong thế kỷ XXI là một công bố năm 2016 của các nhà nghiên cứu tại Tập đoàn công nghệ Microsoft, giới thiệu về “mạng học sâu dư thừa” - hay còn gọi là ResNet. Đây là một dạng mạng nơ-ron nhân tạo, nền tảng cho công nghệ học sâu (deep learning) và nhiều bước tiến vượt bậc trong lĩnh vực AI sau này.
Công trình này mô tả cách huấn luyện các mạng học sâu có tới khoảng 150 tầng - gấp gần 5 lần so với các kiến trúc phổ biến thời điểm đó. ResNet đã giải quyết được vấn đề “tín hiệu suy giảm” khi truyền qua quá nhiều tầng mạng, một rào cản lớn trong huấn luyện AI trước đây. Ý tưởng đằng sau ResNet đã đặt nền móng cho sự phát triển của hàng loạt công cụ AI mang tính cách mạng như AlphaGo (chơi cờ vây), AlphaFold (dự đoán cấu trúc protein) và sau này là các mô hình ngôn ngữ như ChatGPT.
Tuy vậy, bài báo của Microsoft không phải lúc nào cũng đứng đầu trong mọi bảng xếp hạng. Theo Google Scholar - công cụ tìm kiếm học thuật mà chính nhóm phát triển đã gửi dữ liệu cho Nature - bài báo này xếp thứ hai với khoảng 254.000 lượt trích dẫn. Trong khi đó, cơ sở dữ liệu Web of Science (thuộc sở hữu của Clarivate) xếp công trình này ở vị trí thứ ba, với hơn 100.000 lượt trích dẫn. Tuy vậy, khi xét thứ hạng trung vị trong năm cơ sở dữ liệu mà Nature lựa chọn, bài báo của Microsoft có lượt trích dẫn đứng đầu.
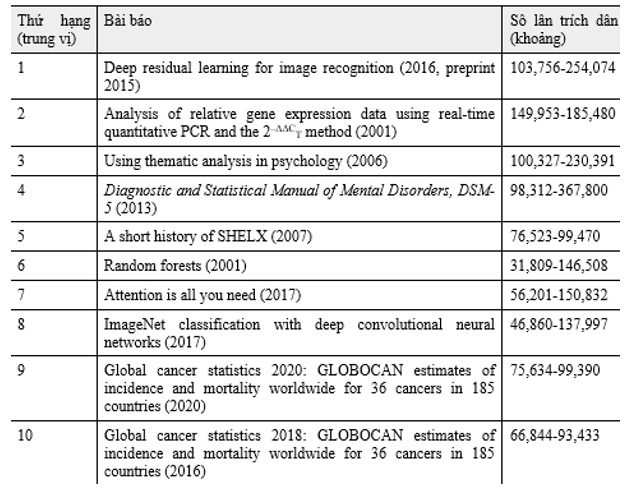
Thống kê số lần trích dẫn của 10 công trình được trích dẫn nhiều nhất (nguồn: Tổng hợp từ: Web of Science, Scopus, OpenAlex, Dimensions, Google Scholar).
AI lên ngôi
Theo “bố già của AI” Geoff Hinton (nhà khoa học máy tính tại Đại học Toronto, Canada, được trao Giải Nobel Vật lý năm 2024), AI có nhiều lợi thế tự nhiên khi xét về mức độ trích dẫn. Ông cho biết, các bài nghiên cứu AI có tính ứng dụng rộng rãi trong nhiều lĩnh vực và sự phát triển thần tốc cùng khối lượng công bố đồ sộ trong thế kỷ XXI đã góp phần thúc đẩy chỉ số trích dẫn. Nhiều người coi cuộc cách mạng deep learning (nơi các mạng nơ-ron nhiều tầng thể hiện sức mạnh vượt trội) bắt đầu từ một bài báo năm 2012 do GS Geoff Hinton đồng tác giả. Công trình này giới thiệu mạng AlexNet, vượt xa các phương pháp khác trong cuộc thi nhận diện hình ảnh. Bài báo hiện đứng thứ 8 trong danh sách được trích dẫn nhiều nhất của thế kỷ XXI. Một bài báo tổng quan khác về deep learning do GS Geoff Hinton viết đang ở vị trí thứ 16. Trong khi đó, bài báo năm 2009 giới thiệu ImageNet - bộ dữ liệu “huyền thoại” giúp huấn luyện các mô hình nhận diện ảnh - đứng thứ 24.
Ba năm sau AlexNet, một nghiên cứu cải tiến kiến trúc mạng nơ-ron dẫn đến mô hình U-net 9 (giúp xử lý hình ảnh hiệu quả hơn với ít dữ liệu huấn luyện hơn) hiện đang xếp thứ 12. Đồng tác giả Olaf Ronneberger (làm việc tại Google DeepMind, Vương quốc Anh) cho biết, bài báo từng suýt bị từ chối tại hội nghị khoa học vì “chưa đủ mới”. Nhưng giờ đây, U-net vẫn là nền tảng chủ lực trong các mô hình khuếch tán tạo ảnh.
Đến năm 2017, các nhà nghiên cứu tại Google tiếp tục tạo dấu ấn với công trình “Attention is all you need” - giới thiệu kiến trúc mạng nơ-ron mới gọi là transformer. Đây là nền tảng của các mô hình ngôn ngữ lớn như ChatGPT, nhờ khả năng tự tập trung (self-attention) để ưu tiên thông tin quan trọng trong quá trình học. Bài báo này hiện xếp thứ 7 trong danh sách.
Một yếu tố khác giúp các bài báo AI được trích dẫn nhiều là tính mở. Phần lớn nghiên cứu học thuật ban đầu trong lĩnh vực này đều là mã nguồn mở, dễ tiếp cận và sử dụng. Ví dụ, bài báo xếp thứ 6 với tiêu đề “Random forests” giới thiệu một thuật toán học máy cải tiến từ các phương pháp trước đó. Phương pháp này được yêu thích vì miễn phí, dễ dùng và cho kết quả tốt ngay cả khi không cần tinh chỉnh.
Phần mềm nghiên cứu: "Viết để được trích dẫn"
Bài báo được trích dẫn nhiều thứ hai là bài báo viết để có thể được trích dẫn. Khoảng 25 năm trước, nhà khoa học dược phẩm Thomas Schmittgen từng gửi một bài báo sử dụng kỹ thuật PCR định lượng (qPCR) để phân tích DNA. Khi trích dẫn công thức từ một tài liệu hướng dẫn kỹ thuật, ông bị phản biện yêu cầu không được dùng tài liệu phi học thuật. Sau đó, ông đã liên hệ với tác giả của công thức và cùng viết lại thành một bài báo chính thức có thể được cộng đồng trích dẫn. Bài báo này đã được trích dẫn hơn 162.000 lần theo cơ sở dữ liệu Web of Science - đưa công trình này lọt top 10 các bài nghiên cứu khoa học được trích dẫn nhiều nhất mọi thời đại. Bài báo được ưa chuộng vì cung cấp công thức đơn giản để các nhà sinh học định lượng sự thay đổi hoạt động gen dưới các điều kiện khác nhau, ví dụ trước và sau điều trị bằng thuốc.
Một phần mềm khác có mục đích tương tự là DESeq2 (xếp thứ 18 trong danh sách) cũng hỗ trợ phân tích sự thay đổi biểu hiện gen nhưng sử dụng dữ liệu giải trình tự RNA. Một phần mềm nghiên cứu khác (xếp thứ 5) là bộ công cụ SHELX của nhà hóa học người Anh - GS George Sheldrick. GS George Sheldrick phát triển SHELX để phân tích mô hình tán xạ của tia X khi chiếu qua tinh thể phân tử, từ đó xác định cấu trúc nguyên tử. GS George Sheldrick bắt đầu công việc này từ những năm 1970 khi ông vừa giảng dạy hóa học, vừa “viết chương trình như một sở thích cá nhân”. Đến năm 2008, ông viết một bài tổng quan và khuyến nghị cộng đồng trích dẫn bài này khi sử dụng SHELX. Hiện công trình này đã được trích dẫn 70.000-90.000 lần, tùy theo cơ sở dữ liệu.
Nghiên cứu ung thư và y tế công cộng
Ba bài báo nằm trong danh sách là các tài liệu quen thuộc trong phần mở đầu của các công trình nghiên cứu về ung thư. Hai trong số đó là GLOBOCAN 2018 và 2020 (xếp thứ 9 và 10) - là các báo cáo do Tổ chức Y tế Thế giới (WHO) công bố định kỳ, cung cấp thống kê toàn cầu về tỷ lệ mắc và tử vong do ung thư. Bài báo thứ ba liên quan đến ung thư (hạng 19) là một bài tổng quan nổi tiếng với mục tiêu cô đọng sự phức tạp của ung thư thành một số đặc điểm cốt lõi mà các khối u thường có - gọi là “các dấu ấn đặc trưng của ung thư” (hallmarks of cancer).
Đứng thứ 4 trong danh sách là tài liệu mà nhiều người gọi là “kinh thánh của ngành tâm thần học”: DSM-5 - phiên bản thứ năm của “Cẩm nang Chẩn đoán và thống kê các rối loạn tâm thần”, được xuất bản năm 2013 sau gần 20 năm kể từ phiên bản trước. Cuốn sách mô tả tiêu chí chẩn đoán và phân loại các rối loạn tâm thần như trầm cảm hay nghiện chất và được sử dụng rộng rãi trong nghiên cứu cũng như thực hành lâm sàng. Đây là cuốn sách duy nhất được Nature đưa vào danh sách, vì hầu hết các cơ sở dữ liệu đều ghi nhận nó như một đầu mục học thuật chính thức.
Cải thiện chất lượng nghiên cứu
Hai nhà tâm lý học Virginia Braun và Victoria Clarke đã quen với việc chỉ nhận được vài lượt trích dẫn cho các nghiên cứu về giới tính và tình dục. Nhưng họ đã vô cùng kinh ngạc khi bài báo năm 2006 của mình vươn lên trở thành bài được trích dẫn nhiều thứ ba của thế kỷ XXI. Trong nhiều năm, họ nhận thấy sinh viên gặp khó khăn khi học phân tích chủ đề (thematic analysis) - một phương pháp nghiên cứu định tính để tìm ra mô hình chung trong dữ liệu như các cuộc phỏng vấn. Họ nhận ra phương pháp này thường bị mô tả mơ hồ, thiếu tiêu chuẩn rõ ràng. Họ viết bài báo này nhắm đến sinh viên, giải thích cụ thể và dễ hiểu về phân tích chủ đề, kèm theo một danh sách tiêu chí thực hành tốt. Bài báo đã nhanh chóng trở thành tài liệu kinh điển trong nghiên cứu định tính - đặc biệt trong các lĩnh vực xã hội học, tâm lý học và giáo dục.
Sự trỗi dậy của các bài tổng quan, phần mềm mã nguồn mở và một bài học từ những trích dẫn “bất ngờ”
Một bài báo khác cũng có ảnh hưởng lớn đến chất lượng nghiên cứu, được công bố năm 2003, mô tả các sai lệch phương pháp học thường gặp trong nghiên cứu hành vi ở các ngành như tâm lý học, quản lý và các lĩnh vực khác. Tác giả chính là Philip Podsakoff, nhà nghiên cứu quản trị tại Đại học Florida (Gainesville, Mỹ). Ông cho biết, nhiều nhà nghiên cứu đã bắt đầu trích dẫn bài của ông trong phần phương pháp để thể hiện rằng họ đã cân nhắc và xử lý các sai lệch tiềm ẩn.
Một xu hướng nổi bật trong danh sách các bài được trích dẫn nhiều nhất là sự bùng nổ của các tổng quan hệ thống và phân tích gộp (systematic review & meta-analysis). Trong đó, các nhà nghiên cứu tổng hợp lại những nghiên cứu nghiêm ngặt nhằm trả lời câu hỏi cụ thể - chẳng hạn, một loại thuốc có thực sự hiệu quả hay không. Phân tích gộp giúp kết hợp kết quả định lượng từ nhiều nghiên cứu khác nhau.
Tuy nhiên, theo PGS David Moher (Viện Nghiên cứu Bệnh viện Ottawa, Canada), nhiều tổng quan hệ thống khi đó được trình bày “một cách cẩu thả”. Thiếu thông tin về đối tượng nghiên cứu, liều lượng thuốc, hoặc quy trình phân tích - những yếu tố then chốt để đánh giá chất lượng nghiên cứu. Để giải quyết vấn đề, năm 2009, PGS David Moher và cộng sự đã công bố hướng dẫn PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses), gồm 27 tiêu chí để đảm bảo bài tổng quan được báo cáo rõ ràng và đầy đủ. Hướng dẫn này được công bố đồng thời trên nhiều tạp chí y học lớn và nhanh chóng trở thành tiêu chuẩn toàn cầu, hiện đứng thứ 11 trong danh sách được trích dẫn nhiều nhất.
Đến năm 2020, gần 200 tạp chí và tổ chức khoa học đã chính thức ủng hộ sử dụng PRISMA và cùng năm đó, PGS David Moher và đồng nghiệp công bố phiên bản cập nhật, hiện cũng đã lọt vào danh sách trích dẫn nhiều nhất (xếp thứ 23). Dù các nghiên cứu cho thấy việc áp dụng PRISMA giúp cải thiện chất lượng bài tổng quan, nhưng PGS David Moher thừa nhận: Vẫn có người “lách luật” bằng cách trích dẫn hướng dẫn nhưng không thực sự tuân thủ các tiêu chí.
Một công cụ thống kê khác cũng lọt vào danh sách được trích dẫn nhiều là chỉ số I², giúp đánh giá mức độ tương đồng giữa các nghiên cứu trong một phân tích gộp. Ví dụ, thuốc giảm cân có hiệu quả như nhau ở nhiều nhóm dân số khác nhau hay không. Chỉ số này được phát triển đầu những năm 2000 bởi GS Julian Higgins, khi ông còn làm việc tại Đơn vị Thống kê sinh học của Hội đồng Nghiên cứu Y khoa (Cambridge, Vương quốc Anh). Nhờ được đưa vào Sổ tay Cochrane - cẩm nang uy tín nhất cho các bài tổng quan hệ thống - công trình của GS Julian Higgins nhanh chóng được trích dẫn rộng rãi.
Các bài báo có trích dẫn cao liên quan đến phần mềm phân tích số liệu và lập trình mã nguồn mở bao gồm: scikit-learn - thư viện Python mã nguồn mở hỗ trợ học máy, đã được trích dẫn hơn 50.000 lần (hoặc 100.000 theo Google Scholar), xếp thứ 15 trong danh sách; lme4 - gói phần mềm trong R dùng cho mô hình thống kê tuyến tính hỗn hợp (mixed-effects models), xếp thứ 14; G*Power - chương trình miễn phí giúp sinh học gia tính cỡ mẫu phù hợp để đạt được ý nghĩa thống kê, xếp thứ 25.
Lê Bắc (lược dịch theo Nature)