Trí tuệ nhân tạo đa phương thức và bài toán hợp nhất dữ liệu mạng xã hội
Sự bùng nổ của mạng xã hội tạo ra nguồn dữ liệu đa phương thức khổng lồ nhưng cũng đặt ra nhiều thách thức về xử lý và phân tích thông tin. Bài viết đề xuất kiến trúc và định hướng triển khai hệ thống kiến trúc AI đa phương thức ứng dụng Transformer và cơ chế chú ý chéo nhằm nâng cao hiệu quả thu thập, hợp nhất và phân tích dữ liệu từ nhiều nguồn trên môi trường số.
Bối cảnh dữ liệu mạng xã hội và yêu cầu mới của phân tích thông tin
Trong những năm gần đây, sự phát triển bùng nổ của các nền tảng mạng xã hội như Facebook, TikTok, Instagram và YouTube đã làm thay đổi căn bản cách con người giao tiếp, chia sẻ thông tin và hình thành dư luận xã hội. Không gian số hiện nay không còn bị giới hạn bởi văn bản mà đã chuyển sang dạng nội dung đa phương thức, nơi văn bản, hình ảnh, video và âm thanh cùng tồn tại và bổ trợ lẫn nhau để truyền tải thông điệp.
Mỗi phút trôi qua, hàng triệu bài đăng, video và bình luận được tạo ra, hình thành một dòng dữ liệu liên tục và khổng lồ. Nguồn dữ liệu này mang giá trị rất lớn trong nhiều lĩnh vực như theo dõi xu hướng thông tin, phân tích xu hướng xã hội, phát hiện tin giả, nghiên cứu hành vi người dùng và hỗ trợ ra quyết định chính sách. Tuy nhiên, việc khai thác hiệu quả nguồn tài nguyên này vẫn đang đối mặt với nhiều thách thức kỹ thuật phức tạp.
Thách thức đầu tiên là khoảng cách ngữ nghĩa (semantic gap) giữa các phương thức dữ liệu. Các mô hình xử lý đơn phương thức truyền thống thường chỉ tập trung vào văn bản hoặc hình ảnh riêng lẻ, dẫn đến việc bỏ qua mối quan hệ ngữ cảnh giữa chúng. Ví dụ, một hình ảnh có thể mang ý nghĩa hoàn toàn khác khi đi kèm với một dòng chú thích cụ thể.
Thách thức thứ hai là tính nhiễu và phi cấu trúc của dữ liệu mạng xã hội. Người dùng thường sử dụng ngôn ngữ lóng, viết tắt, emoji hoặc nội dung đa phương tiện có chất lượng không đồng nhất, gây khó khăn cho việc trích xuất thông tin chính xác.
Thách thức thứ ba là yêu cầu xử lý thời gian thực. Tốc độ lan truyền thông tin trên mạng xã hội rất nhanh, đòi hỏi hệ thống phải có khả năng thu thập và phân tích gần như tức thời để đảm bảo tính kịp thời của kết quả.
Trong bối cảnh đó, các kiến trúc học sâu truyền thống như CNN - Mạng nơron tích chập (Convolutional Neural Network - một loại mạng học sâu chuyên xử lý dữ liệu dạng hình ảnh hoặc không gian 2D/3D) hay RNN - mạng nơron hồi quy (Recurrent Neural Network - được thiết kế để xử lý dữ liệu dạng chuỗi) bộc lộ nhiều hạn chế khi xử lý dữ liệu đa phương thức. Sự xuất hiện của Transformer và cơ chế Attention đã mở ra một hướng tiếp cận mới, cho phép xây dựng các hệ thống AI đa phương thức có khả năng hiểu và hợp nhất dữ liệu hiệu quả hơn.
Công nghệ xử lý dữ liệu trí tuệ nhân tạo đa phương thức
Khái niệm AI đa phương thức: AI đa phương thức là một thế hệ trí tuệ nhân tạo tiên tiến có khả năng xử lý và tích hợp đồng thời nhiều loại dữ liệu đầu vào khác nhau như văn bản, hình ảnh, âm thanh và video. Trong học máy, mỗi loại dữ liệu này được gọi là một phương thức (modality). Điểm khác biệt cốt lõi của AI đa phương thức so với các hệ thống truyền thống là khả năng hiểu mối quan hệ giữa các phương thức. Thay vì phân tích độc lập từng loại dữ liệu, hệ thống có thể xây dựng một không gian biểu diễn chung, nơi các thông tin được liên kết và bổ trợ cho nhau. Một hệ thống AI đa phương thức điển hình bao gồm ba thành phần chính: mô-đun đầu vào chịu trách nhiệm trích xuất đặc trưng từ từng phương thức; mô-đun hợp nhất đóng vai trò tích hợp các đặc trưng này; và mô-đun đầu ra thực hiện các tác vụ như phân loại, dự đoán hoặc tạo nội dung.
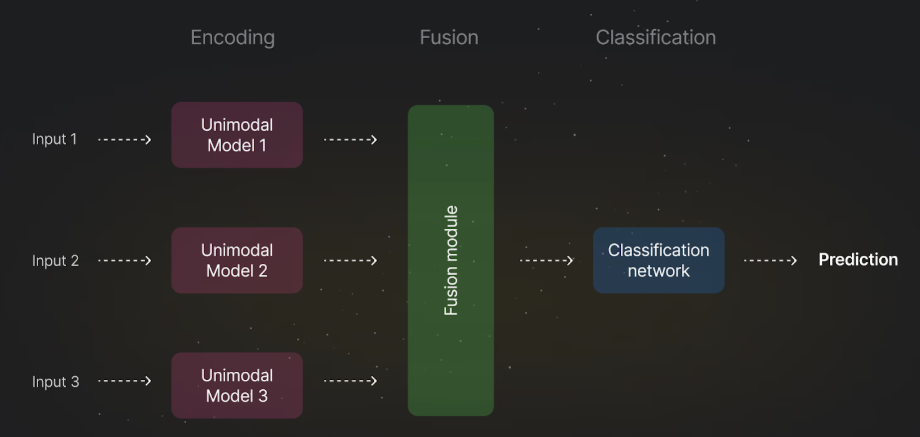
Các công nghệ nền tảng: Sự phát triển của AI đa phương thức dựa trên sự kết hợp của nhiều công nghệ cốt lõi. Học sâu và Transformer đóng vai trò trung tâm trong việc xử lý dữ liệu phức tạp. Transformer với cơ chế Attention cho phép mô hình xác định các thành phần quan trọng trong dữ liệu và học được mối quan hệ giữa chúng, kể cả khi dữ liệu có độ dài lớn hoặc cấu trúc không đồng nhất. Xử lý ngôn ngữ tự nhiên (NLP) giúp hệ thống hiểu được ý nghĩa của văn bản, bao gồm cả ngữ cảnh và sắc thái cảm xúc. Đây là thành phần quan trọng vì văn bản vẫn là phương thức chính trong giao tiếp số. Thị giác máy tính cung cấp khả năng phân tích hình ảnh và video, từ nhận diện đối tượng đến hiểu bối cảnh. Sự kết hợp giữa CNN và Vision Transformer (ViT) đã nâng cao đáng kể hiệu suất trong lĩnh vực này. Xử lý âm thanh hỗ trợ nhận diện giọng nói, phân tích cảm xúc và tổng hợp tiếng nói, đóng vai trò quan trọng trong các nội dung video và podcast. Sự kết hợp các công nghệ này giúp AI đa phương thức có thể xử lý đồng thời văn bản, hình ảnh và âm thanh theo cách gần với khả năng tiếp nhận thông tin của con người.
Kiến trúc hệ thống đề xuất
Hệ thống được thiết kế theo mô hình phân tầng nhằm đảm bảo khả năng mở rộng và xử lý song song. Kiến trúc gồm bốn lớp chính.
Lớp thu thập và lưu trữ dữ liệu: Hệ thống sử dụng các API (Application Programming Interface - giao diện lập trình ứng dụng) chính thống và kỹ thuật thu thập dữ liệu công khai theo cơ chế cho phép của nền tảng để thu thập dữ liệu từ nhiều nền tảng mạng xã hội. Dữ liệu sau khi thu thập được đưa vào hệ thống xử lý dòng (streaming) như Apache Kafka, cho phép xử lý theo thời gian thực và giảm thiểu độ trễ. Về lưu trữ, hệ thống áp dụng mô hình kết hợp giữa cơ sở dữ liệu quan hệ, NoSQL - hệ cơ sở dữ liệu phi quan hệ và lưu trữ đối tượng. Các dữ liệu đa phương tiện được lưu trữ riêng biệt, trong khi metadata được lưu trong cơ sở dữ liệu có cấu trúc. Đặc biệt, các vector đặc trưng được lưu trữ trong cơ sở dữ liệu vector, cho phép thực hiện các truy vấn tìm kiếm tương đồng với tốc độ cao.
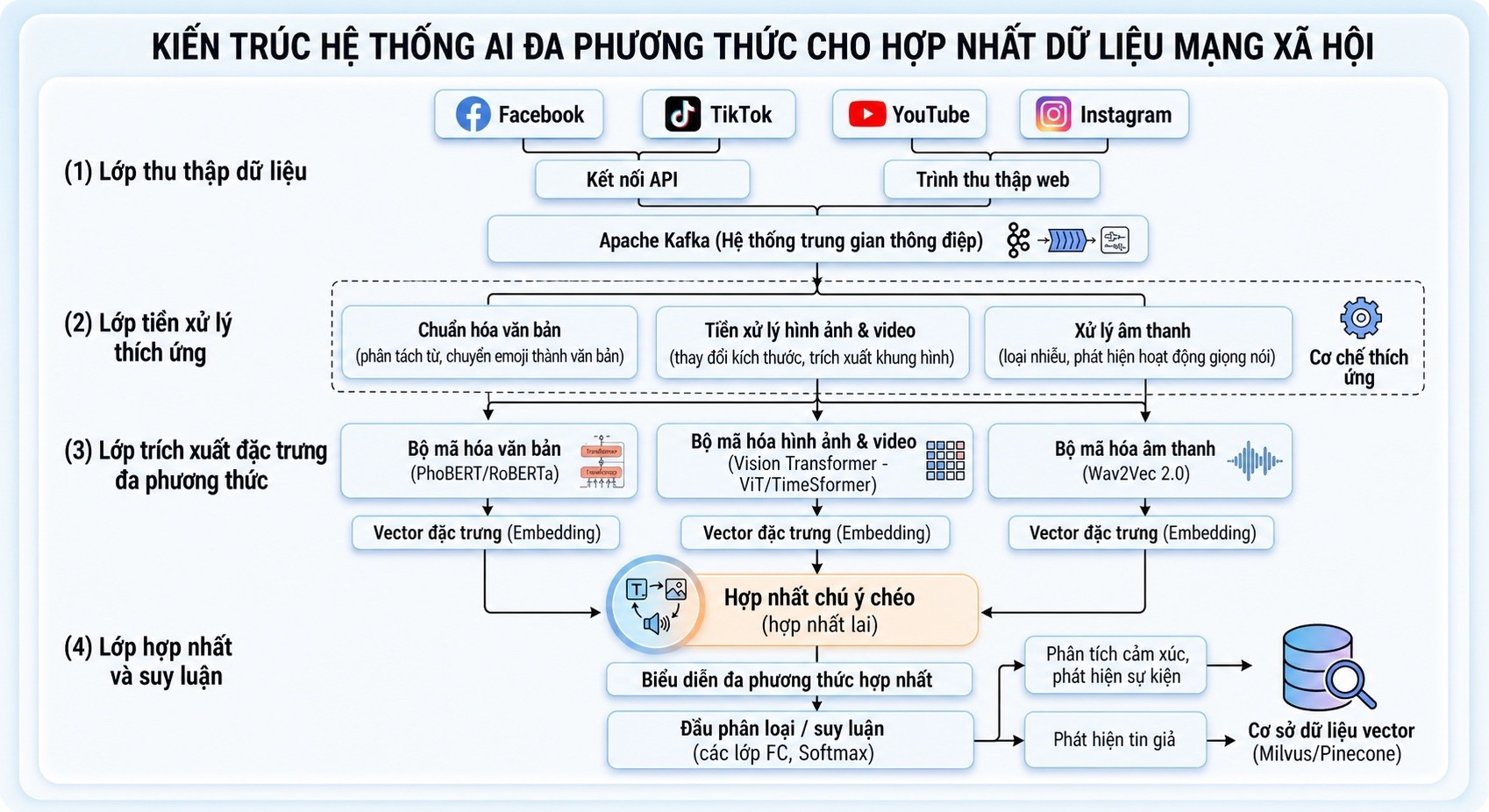
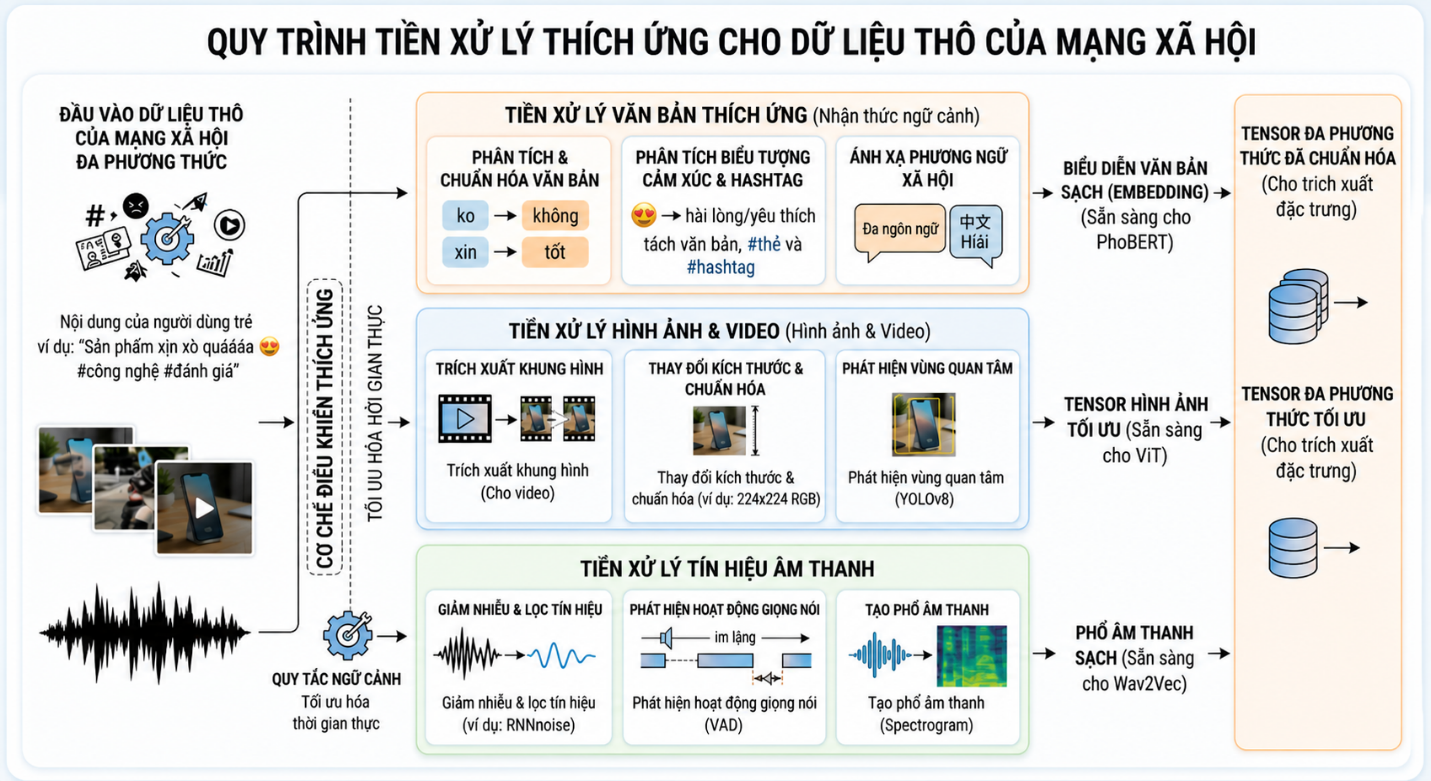
Lớp tiền xử lý: Dữ liệu mạng xã hội thường chứa nhiều nhiễu và không đồng nhất, do đó cần một bước tiền xử lý mạnh. Đối với văn bản, hệ thống thực hiện chuẩn hóa ngôn ngữ, xử lý emoji và loại bỏ các thành phần dư thừa. Đối với hình ảnh, các kỹ thuật chuẩn hóa và tăng cường dữ liệu được áp dụng để cải thiện chất lượng đầu vào. Đối với video, hệ thống chỉ trích xuất các khung hình quan trọng nhằm giảm chi phí xử lý. Đối với âm thanh, các kỹ thuật khử nhiễu và phân đoạn được sử dụng để loại bỏ tạp âm.
Lớp trích xuất đặc trưng: Hệ thống sử dụng các mô hình chuyên biệt cho từng phương thức. Văn bản được xử lý bằng các mô hình Transformer như PhoBERT, hình ảnh được xử lý bằng Vision Transformer và âm thanh được xử lý bằng Wav2Vec. Các đặc trưng được chuyển thành vector số học và chuẩn hóa về cùng một không gian biểu diễn, tạo tiền đề cho quá trình hợp nhất.
Lớp hợp nhất và suy diễn: Cơ chế hợp nhất lai kết hợp kỹ thuật chú ý chéo cho phép các phương thức tương tác với nhau. Văn bản có thể “truy vấn” hình ảnh để xác định đối tượng liên quan, trong khi hình ảnh có thể bổ sung ngữ cảnh cho văn bản. Quá trình hợp nhất gồm hai giai đoạn: hợp nhất thực thể và hợp nhất ngữ nghĩa. Kết quả là một vector đa phương thức chứa đầy đủ thông tin của bài đăng. Vector này được sử dụng để thực hiện các tác vụ như phân tích cảm xúc, phát hiện tin giả hoặc nhận diện sự kiện.
Giải pháp ứng dụng và triển khai
Bảng 1. Hệ sinh thái công cụ đề xuất.
| Thành phần | Công cụ đề xuất | Chức năng |
| Thu thập (Ingestion) | Apache Kafka | Điều phối dòng dữ liệu (Streaming) từ Facebook/TikTok API, đảm bảo không mất dữ liệu khi tải cao. |
| Xử lý phân tán | Apache Spark | Tiền xử lý song song khối lượng lớn văn bản và trích xuất Frame video trên quy mô Cluster. |
| Lưu trữ Vector | Milvus / Pinecone | Lưu trữ các "Embeddings" đa phương thức để thực hiện tìm kiếm tương đồng (Similarity Search) cực nhanh. |
| AI Framework | PyTorch / Hugging Face | Triển khai các mô hình Transformer (PhoBERT, ViT) và quản lý Pipeline huấn luyện. |
| Phân tích Real-time | Streamlit/Grafana | Xây dựng Dashboard theo dõi xu hướng và cảnh báo tin giả thời gian thực. |
Hệ thống có thể được triển khai trên nền tảng các công cụ mã nguồn mở như Kafka, Spark, PyTorch và Milvus, cho phép xử lý dữ liệu quy mô lớn. Một ứng dụng tiêu biểu là phát hiện tin giả đa phương thức. Hệ thống có thể so sánh nội dung giữa văn bản và hình ảnh để phát hiện mâu thuẫn, đồng thời phân tích cảm xúc từ nhiều nguồn dữ liệu để đánh giá tính xác thực. Ngoài ra, quy trình MLOps (Machine Learning Operations - vận hành và quản lý vòng đời mô hình học máy) được áp dụng để đảm bảo hệ thống có thể vận hành ổn định, cập nhật linh hoạt và học liên tục từ dữ liệu mới. Để tối ưu tài nguyên, kỹ thuật chắt lọc tri thức mô hình (Knowledge Distillation) được sử dụng nhằm giảm chi phí tính toán, cho phép triển khai hệ thống trên quy mô lớn mà vẫn đảm bảo hiệu quả.
Kết luận
Nghiên cứu đã đề xuất một kiến trúc AI đa phương thức để tối ưu hóa cho việc thu thập và hợp nhất dữ liệu phức tạp trên mạng xã hội. Bằng cách kết hợp các mô hình nền tảng tiên tiến như PhoBERT, ViT cùng cơ chế Chú ý chéo (Cross-Attention), kiến trúc đề xuất cho thấy tiềm năng giải quyết bài toán rời rạc giữa văn bản, hình ảnh, âm thanh và video. Việc hợp nhất dữ liệu không chỉ nâng cao độ chính xác trong phân tích sắc thái và phát hiện tin giả mà còn tối ưu hóa hiệu suất vận hành nhờ hệ sinh thái công cụ Kafka, Spark và Milvus. Đây là nền tảng quan trọng cho các hệ thống theo dõi xu hướng thông tin thông minh, mở ra hướng phát triển mới trong việc quản trị nội dung số và phản ứng nhanh trước các biến động xã hội trong kỷ nguyên AI thế hệ mới./.
TÀI LIỆU THAM KHẢO
[1] B.S. Nayak (2025), “The Evolution and Architecture of Multimodal AI Systems”, Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol, 11(1), pp.1007-1017, DOI: 10.32628/CSEIT251112108.
[2] F. Krones, U. Marikkar, G. Parsons, et al. (2025), "Review of multimodal machine learning approaches in healthcare", Information Fusion, 114, DOI: 10.1016/j.inffus.2024.102690.
[3] S.N. Wadekar, A. Chaurasia, A. Chadha, et al. (2024), "The evolution of multimodal model architectures", https://arxiv.org/pdf/2405.17927v1, accessed 15 April 2026.
[4] D. Roy, B. Salehi, S. Banou, et al. (2023), "Going beyond RF: A survey on how AI-enabled multimodal beamforming will shape the NextG standard", Computer Networks, 228, DOI: 10.1016/j.comnet.2023.109729.
[5] M. Zhang, Q. Huang, H. Liu (2022), “A multimodal data analysis approach to social media during natural disasters”, Sustainability, 14, DOI: 10.3390/su14095536.
(1) Viện Công nghệ thông tin, Viện Hàn lâm Khoa học và Công nghệ Việt Nam;
(2) Trung tâm Vũ trụ Việt Nam, Viện Hàn lâm Khoa học và Công nghệ Việt Nam;
(3) Trung tâm Dữ liệu và Thông tin khoa học, Viện Hàn lâm Khoa học và Công nghệ Việt Nam.